Introduction#
Framework#
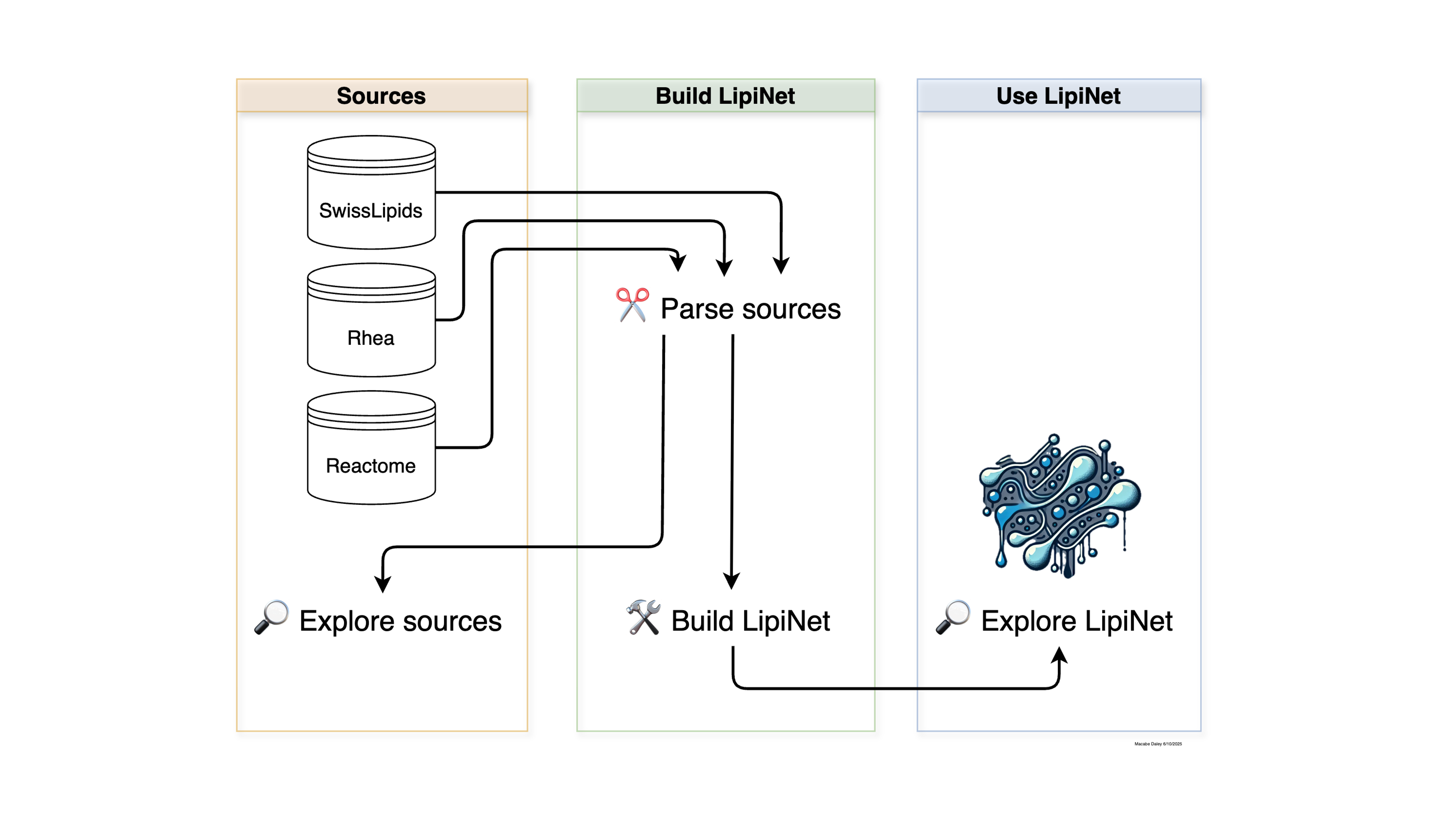
The general framework for LipiNet follows a simple three-stage process for building and exploring lipid-centric knowledge networks:
Parse and standardize datasets - Import lipid-related information from key biochemical resources such as SwissLipids, Rhea, and Reactome. These data are cleaned, harmonized, and converted into graph-ready formats. See the Build LipiNet section.
Explore and analyse the data - Investigate parsed data to understand lipid classes, biochemical reactions, and molecular relationships. This step includes generating network representations and basic analyses to reveal structure and connectivity. See the Explore Sources section.
Integrate and extend the network - Combining multiple parsed sources into a single unified lipid knowledge graph, enabling cross-database queries, pathway-level insights, and advanced visualisations for downstream analyses. See the Use LipiNet section.
Why is this important?#
The lipidomics field faces unique challenges in standardizing its nomenclature and measurement precision, unlike genomics, transcriptomics, and proteomics, which have relatively consistent units of measurement (genes, transcripts, proteins). In lipidomics, measurement limitations frequently prevent analysts from identifying lipids at precise structural or isomeric subspecies levels. Consequently, lipid identification often relies on generalized representations, such as abstract class or species names aligned with established ontologies. This, along with variations in database standards, creates a particularly fragmented and complex landscape for prior knowledge in lipidomics.
LipiNet is designed to address these challenges by integrating information across disparate lipidomics databases, each with different identifiers and varying levels of lipid resolution. By unifying these resources and accounting for the inherent ambiguity in lipid identification, LipiNet enables more cohesive and comprehensive network analyses across lipidomics databases.
TLDR: Core features#
Multi-layered network construction and analysis
Cross-database lipid identifier integration
Tools for filtering, analysing and visualising by layers