Explore Rhea#
Exploring Rhea from a network perspective
Loading the node and edge info#
from lipinet.parse_rhea import parse_rhea_data
rhea_results = parse_rhea_data(verbose=False)
df_rhea_nodes = rhea_results['df_nodes']
df_rhea_edges = rhea_results['df_edges']
df_rhea_nodes
| node_id | Equation | ChEBI identifier | chebi_name | EC number | Enzymes | Gene Ontology | Cross-reference (Reactome) | layer | ec_level | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | RHEA:21252 | (S)-2-hydroxyglutarate + A = 2-oxoglutarate + AH2 | CHEBI:16782;CHEBI:13193;CHEBI:16810;CHEBI:17499 | (S)-2-hydroxyglutarate;A;2-oxoglutarate;AH2 | EC:1.1.99.2 | 4258.0 | GO:0047545 2-hydroxyglutarate dehydrogenase ac... | NaN | rhea_reactionid | NaN |
| 1 | RHEA:21256 | 3-phosphoshikimate + phosphoenolpyruvate = 5-O... | CHEBI:145989;CHEBI:58702;CHEBI:57701;CHEBI:43474 | 3-phosphoshikimate;phosphoenolpyruvate;5-O-(1-... | EC:2.5.1.19 | 44340.0 | GO:0003866 3-phosphoshikimate 1-carboxyvinyltr... | NaN | rhea_reactionid | NaN |
| 2 | RHEA:21260 | [thioredoxin]-disulfide + L-methionine + H2O =... | CHEBI:50058;CHEBI:57844;CHEBI:15377;CHEBI:5877... | L-cystine residue;L-methionine;H2O;L-methionin... | EC:1.8.4.14 | 3112.0 | GO:0033745 L-methionine-(R)-S-oxide reductase ... | NaN | rhea_reactionid | NaN |
| 3 | RHEA:21264 | glycolate + A = glyoxylate + AH2 | CHEBI:29805;CHEBI:13193;CHEBI:36655;CHEBI:17499 | glycolate;A;glyoxylate;AH2 | EC:1.1.99.14 | 14321.0 | GO:0019154 glycolate dehydrogenase activity | NaN | rhea_reactionid | NaN |
| 4 | RHEA:21268 | (R)-canadine + 2 NADP(+) = berberine + 2 NADPH... | CHEBI:18146;CHEBI:58349;CHEBI:16118;CHEBI:5778... | (R)-canadine;NADP(+);berberine;NADPH;H(+) | EC:1.5.1.31 | 0.0 | GO:0050623 berberine reductase activity | NaN | rhea_reactionid | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 37990 | EC:1.14.13.35 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | rhea_ec | full_ec |
| 37991 | EC:2.5.1.59 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | rhea_ec | full_ec |
| 37992 | EC:2.5.1.60 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | rhea_ec | full_ec |
| 37993 | EC:2.7.7.6 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | rhea_ec | full_ec |
| 37994 | EC:2.7.7.48 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | rhea_ec | full_ec |
37995 rows × 10 columns
df_rhea_edges
| source_id | target_id | ec_level | source_layer | target_layer | interlayer | edge_type | |
|---|---|---|---|---|---|---|---|
| 0 | EC:1 | EC:1.1 | main_class->subclass | rhea_ec | rhea_ec | False | ec_hierarchy |
| 1 | EC:2 | EC:2.5 | main_class->subclass | rhea_ec | rhea_ec | False | ec_hierarchy |
| 2 | EC:1 | EC:1.8 | main_class->subclass | rhea_ec | rhea_ec | False | ec_hierarchy |
| 3 | EC:1 | EC:1.5 | main_class->subclass | rhea_ec | rhea_ec | False | ec_hierarchy |
| 4 | EC:6 | EC:6.3 | main_class->subclass | rhea_ec | rhea_ec | False | ec_hierarchy |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 108434 | RHEA:21240 | EC:2.5.1.59 | NaN | rhea_reactionid | rhea_ec | False | reaction_ec |
| 108435 | RHEA:21240 | EC:2.5.1.60 | NaN | rhea_reactionid | rhea_ec | False | reaction_ec |
| 108436 | RHEA:21244 | EC:2.1.1.70 | NaN | rhea_reactionid | rhea_ec | False | reaction_ec |
| 108437 | RHEA:21248 | EC:2.7.7.6 | NaN | rhea_reactionid | rhea_ec | False | reaction_ec |
| 108438 | RHEA:21248 | EC:2.7.7.48 | NaN | rhea_reactionid | rhea_ec | False | reaction_ec |
108439 rows × 7 columns
from graph_tool.all import Graph, GraphView, graph_draw
import graph_tool as gt
from onionnet import OnionNet
import onionnet.visualisation
import pandas as pd
import onionnet.exporter
Building the network with OnionNet#
onion = OnionNet()
onion.grow_onion(df_nodes=df_rhea_nodes,
df_edges=df_rhea_edges,
node_prop_cols=df_rhea_nodes.columns.to_list(),
edge_prop_cols=df_rhea_edges.columns.to_list(),
drop_na=True,
drop_duplicates=True)
onion.core.graph
<Graph object, directed, with 37995 vertices and 98225 edges, 12 internal vertex properties, 7 internal edge properties, at 0x307136870>
list(onion.core.graph.vp)
['layer_hash',
'node_id_hash',
'node_id',
'Equation',
'ChEBI identifier',
'chebi_name',
'EC number',
'Enzymes',
'Gene Ontology',
'Cross-reference (Reactome)',
'layer',
'ec_level']
df_rhea_nodes.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 37995 entries, 0 to 37994
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 node_id 37995 non-null object
1 Equation 17783 non-null object
2 ChEBI identifier 17783 non-null object
3 chebi_name 31506 non-null object
4 EC number 7569 non-null object
5 Enzymes 17783 non-null float64
6 Gene Ontology 4385 non-null object
7 Cross-reference (Reactome) 913 non-null object
8 layer 37995 non-null object
9 ec_level 6489 non-null object
dtypes: float64(1), object(9)
memory usage: 2.9+ MB
Decode property labels that were encoded
onion.decode_property_labels_bulk(df=df_rhea_nodes, encoded_prop_type='v')
V property 'node_id_decoded' created successfully.
V property 'equation_decoded' created successfully.
V property 'chebi_identifier_decoded' created successfully.
V property 'chebi_name_decoded' created successfully.
V property 'ec_number_decoded' created successfully.
Enzymes prop left as is, no decoding needed (not an object type)
V property 'gene_ontology_decoded' created successfully.
V property 'cross_reference_reactome_decoded' created successfully.
V property 'layer_decoded' created successfully.
V property 'ec_level_decoded' created successfully.
onion.decode_property_labels_bulk(df=df_rhea_edges, encoded_prop_type='e')
E property 'source_id_decoded' created successfully.
E property 'target_id_decoded' created successfully.
E property 'ec_level_decoded' created successfully.
E property 'source_layer_decoded' created successfully.
E property 'target_layer_decoded' created successfully.
interlayer prop left as is, no decoding needed (not an object type)
E property 'edge_type_decoded' created successfully.
df_rhea_edges.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 108439 entries, 0 to 108438
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 source_id 108439 non-null object
1 target_id 98225 non-null object
2 ec_level 6482 non-null object
3 source_layer 108439 non-null object
4 target_layer 108439 non-null object
5 interlayer 108439 non-null bool
6 edge_type 108439 non-null object
dtypes: bool(1), object(6)
memory usage: 5.1+ MB
onion.core.layer_code_to_name
{0: 'rhea_reactionid', 1: 'rhea_chebiid', 2: 'rhea_ec'}
Filtering the network#
Getting all the EC nodes and visualising#
filter1 = lambda v: onion.core.graph.vp['layer_decoded'][v] == 'rhea_ec'
filtered_view = onion.searcher.compose_filters(filter_funcs=[filter1], mode="or")
filtered_view
<GraphView object, directed, with 6489 vertices and 6482 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x30667fe00, at 0x30c3f5250>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x30667fe00, at 0x16dee7980>, False), at 0x30667fe00>
onionnet.exporter.export_info(filtered_view, mode='v')
| v_int | layer_hash | node_id_hash | node_id | Equation | ChEBI identifier | chebi_name | EC number | Enzymes | Gene Ontology | ... | ec_level | node_id_decoded | equation_decoded | chebi_identifier_decoded | chebi_name_decoded | ec_number_decoded | gene_ontology_decoded | cross_reference_reactome_decoded | layer_decoded | ec_level_decoded | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 31506 | 2 | 31506 | 31506 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 1 | EC:1 | nan | nan | nan | nan | nan | nan | rhea_ec | main_class |
| 1 | 31507 | 2 | 31507 | 31507 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 1 | EC:2 | nan | nan | nan | nan | nan | nan | rhea_ec | main_class |
| 2 | 31508 | 2 | 31508 | 31508 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 1 | EC:6 | nan | nan | nan | nan | nan | nan | rhea_ec | main_class |
| 3 | 31509 | 2 | 31509 | 31509 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 1 | EC:3 | nan | nan | nan | nan | nan | nan | rhea_ec | main_class |
| 4 | 31510 | 2 | 31510 | 31510 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 1 | EC:5 | nan | nan | nan | nan | nan | nan | rhea_ec | main_class |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6484 | 37990 | 2 | 37990 | 37990 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 4 | EC:1.14.13.35 | nan | nan | nan | nan | nan | nan | rhea_ec | full_ec |
| 6485 | 37991 | 2 | 37991 | 37991 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 4 | EC:2.5.1.59 | nan | nan | nan | nan | nan | nan | rhea_ec | full_ec |
| 6486 | 37992 | 2 | 37992 | 37992 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 4 | EC:2.5.1.60 | nan | nan | nan | nan | nan | nan | rhea_ec | full_ec |
| 6487 | 37993 | 2 | 37993 | 37993 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 4 | EC:2.7.7.6 | nan | nan | nan | nan | nan | nan | rhea_ec | full_ec |
| 6488 | 37994 | 2 | 37994 | 37994 | 17783 | 17258 | 30647 | 13 | NaN | 6 | ... | 4 | EC:2.7.7.48 | nan | nan | nan | nan | nan | nan | rhea_ec | full_ec |
6489 rows × 22 columns
At first it might look like we have an error here with the Equation, ChEBI identifier, chebi_name and EC number values, afterall why would the ChEBI Identifier values for all EC cells be 17093?
But remember that these are the column values as encoded values; we are more interested instead in their values after decoding (e.g. chebi_identifier_decoded). In which case they are all nan, as we would expect since these EC numbers don’t have ChEBI values etc.
onionnet.exporter.export_info(filtered_view, mode='v')[['layer_decoded','ec_level_decoded']].value_counts()
layer_decoded ec_level_decoded
rhea_ec full_ec 6153
subsubclass 253
subclass 76
main_class 7
Name: count, dtype: int64
Now we can view the 7 ‘families’ of Enzyme Classifications
graph_draw(
filtered_view,
vertex_text=filtered_view.vp['node_id_decoded'],
vertex_text_position=-2,
vertex_size=4,
vertex_text_color='black'
)

<VertexPropertyMap object with value type 'vector<double>', for Graph 0x30667fe00, at 0x306ef8380>
Getting specific nodes based on the reaction IDs (e.g. RHEA:23128)#
# search for a specific node (noi = node of interest)
noi = onion.get_vertex_by_name_tuple(layer_name='rhea_reactionid', node_id_str='RHEA:23128')
onion.searcher.search(start_node_idx=noi,
max_dist=2,
node_text_prop='node_id_decoded',
vertex_text_position=-1,
vertex_size=20)
Filtered graph contains 8 vertices and 7 edges.
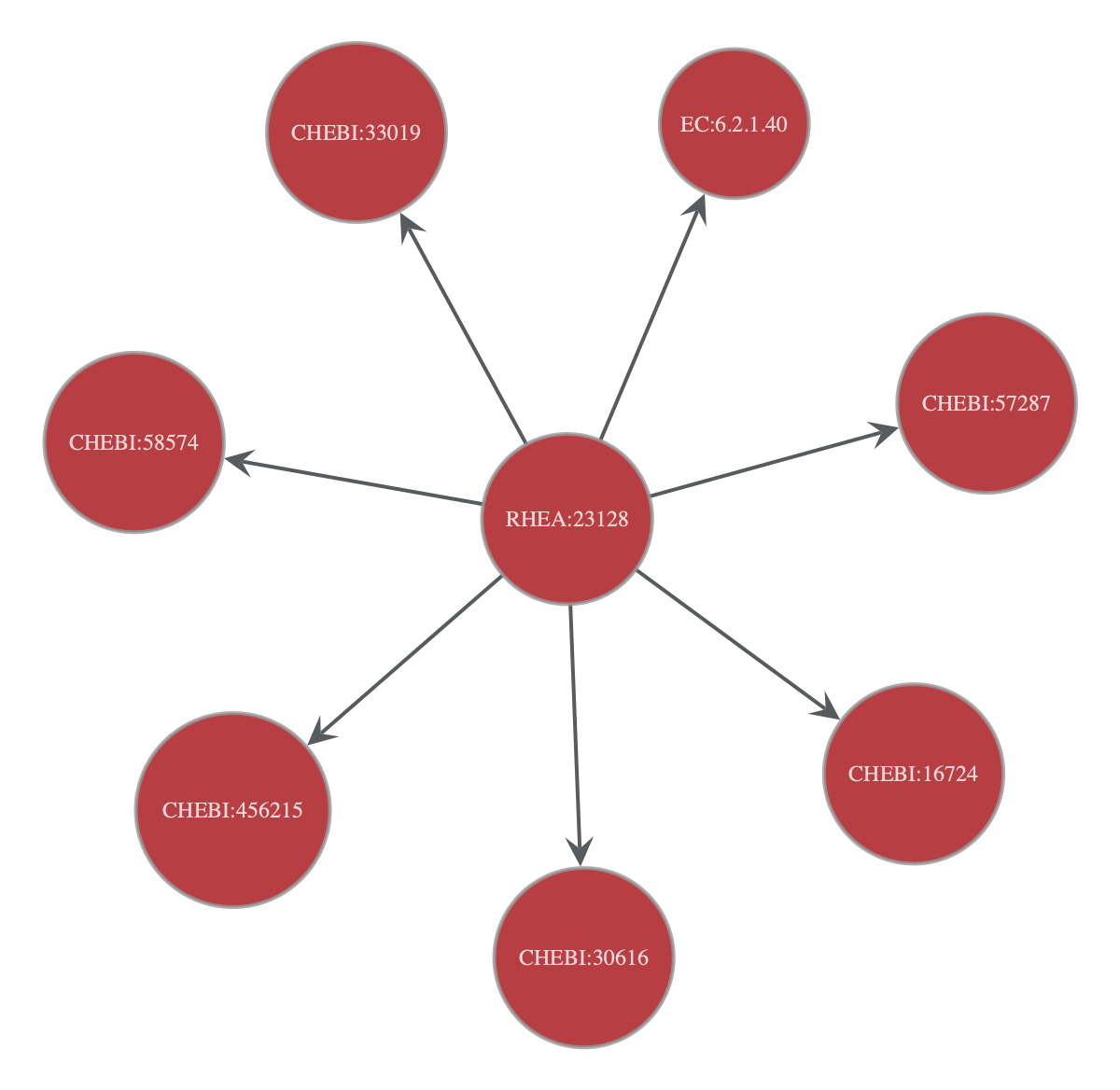
<GraphView object, directed, with 8 vertices and 7 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x1049288c0, at 0x16dee7200>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x1049288c0, at 0x31518e5d0>, False), at 0x1049288c0>
df_rhea_edges[df_rhea_edges['target_layer']=='rhea_chebiid']['target_id'].value_counts()[:30]
target_id
CHEBI:15378 9932
CHEBI:15377 6485
CHEBI:15379 2851
CHEBI:57287 1567
CHEBI:58349 1335
CHEBI:57783 1329
CHEBI:30616 1328
CHEBI:57540 1207
CHEBI:33019 1188
CHEBI:57945 1136
CHEBI:16526 1058
CHEBI:43474 1029
CHEBI:59789 935
CHEBI:456216 865
CHEBI:58210 861
CHEBI:57856 854
CHEBI:57618 852
CHEBI:58223 637
CHEBI:28938 543
CHEBI:456215 529
CHEBI:13193 475
CHEBI:17499 475
CHEBI:16240 461
CHEBI:16810 449
CHEBI:57288 381
CHEBI:30031 349
CHEBI:29033 266
CHEBI:33738 263
CHEBI:33737 263
CHEBI:29101 259
Name: count, dtype: int64
Getting specific nodes based on the chebi IDs (e.g. CHEBI:29101)#
# search for a specific node (noi = node of interest)
noi = onion.get_vertex_by_name_tuple(layer_name='rhea_chebiid', node_id_str='CHEBI:29101')
onion.searcher.search(start_node_idx=noi,
max_dist=4,
node_text_prop='node_id_decoded',
vertex_text_position=-1,
vertex_size=5,
direction='bi')
Filtered graph contains 260 vertices and 259 edges.
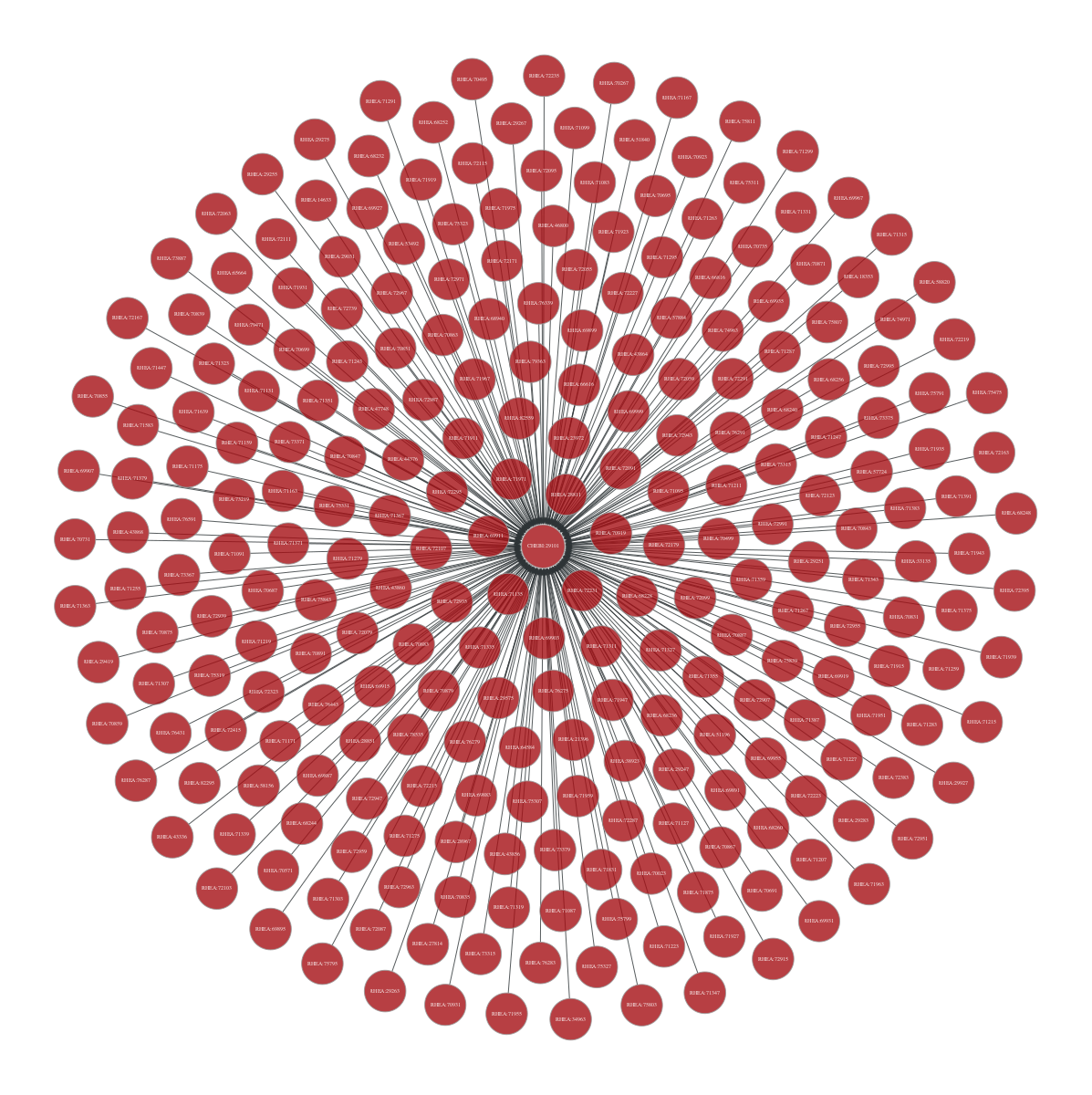
<GraphView object, directed, with 260 vertices and 259 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x31518fb00, at 0x16e0ef2c0>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x31518fb00, at 0x3161665d0>, False), at 0x31518fb00>
Getting all nodes up and/or downstream of a particular EC number (e.g. EC:6.2.1.40)#
We can begin with a bidirectional search of a certain EC number (note this was in the visualisation filter we did earlier)
# search for a specific node (noi = node of interest)
noi = onion.get_vertex_by_name_tuple(layer_name='rhea_ec', node_id_str='EC:6.2.1.40')
onion.searcher.search(start_node_idx=noi,
max_dist=4,
node_text_prop='node_id_decoded',
vertex_text_position=-1,
vertex_size=15,
direction='bi')
Filtered graph contains 5 vertices and 4 edges.

<GraphView object, directed, with 5 vertices and 4 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x31518ce00, at 0x316164f20>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x31518ce00, at 0x316165460>, False), at 0x31518ce00>
Or we could also pick a higher level of EC and then get all the children of that node
# search for a specific node (noi = node of interest)
noi = onion.get_vertex_by_name_tuple(layer_name='rhea_ec', node_id_str='EC:6.2.1')
onion.searcher.search(start_node_idx=noi,
max_dist=4,
node_text_prop='node_id_decoded',
vertex_text_position=-1,
vertex_size=13,
direction='bi')
Filtered graph contains 75 vertices and 74 edges.
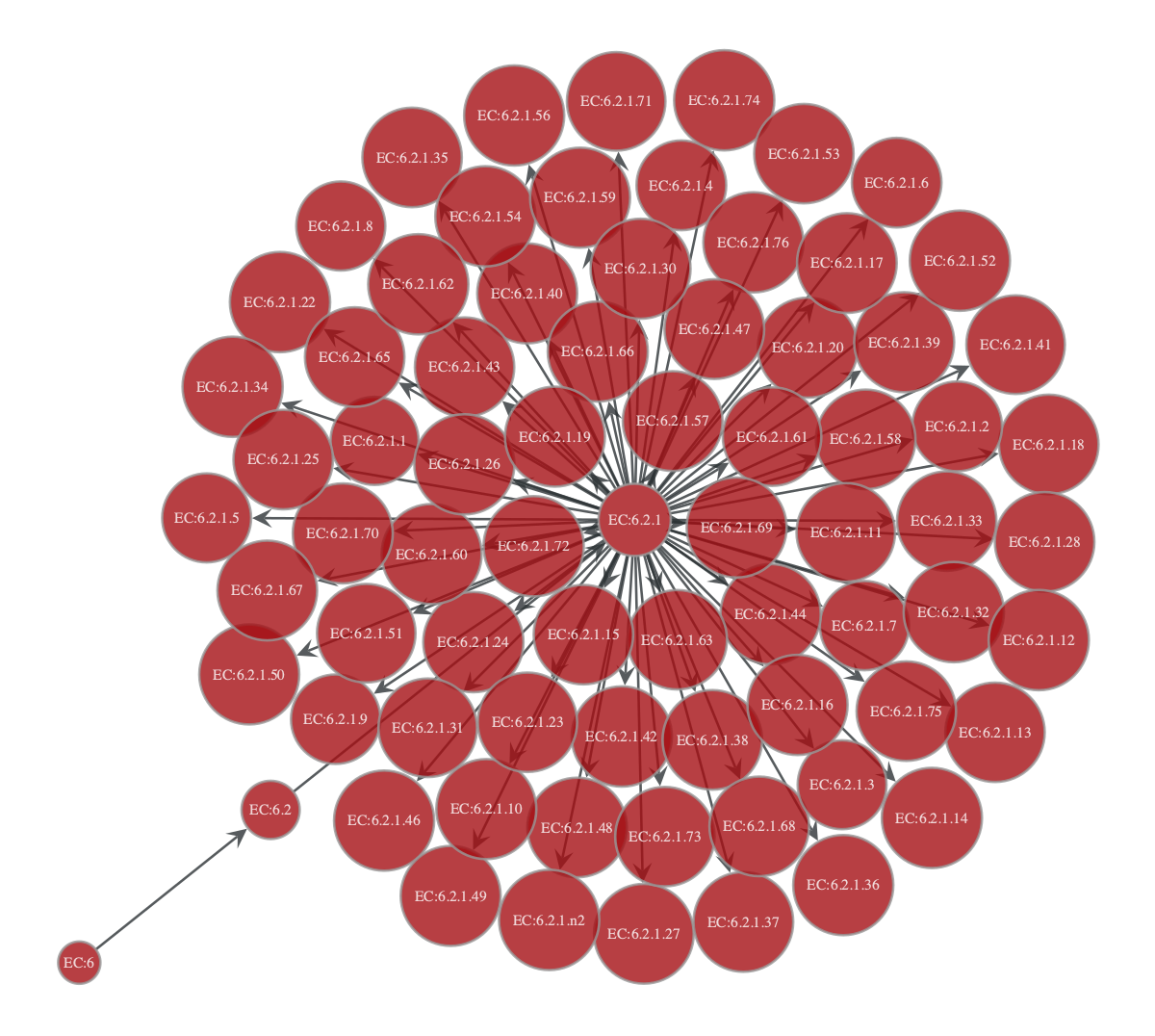
<GraphView object, directed, with 75 vertices and 74 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x307136750, at 0x316165700>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x307136750, at 0x316165190>, False), at 0x307136750>
Combining multiple conditional filters using lambda and onion.compose_filters()#
We can combine filters using lambda and onion.compose_filters(). We can use either and or or modes.
For example we might want to filter those nodes where the ec_level_decoded is either main class or subclass.
filter1 = lambda v: onion.core.graph.vp['ec_level_decoded'][v] == 'main_class'
filter2 = lambda v: onion.core.graph.vp['ec_level_decoded'][v] == 'subclass'
filtered_view = onion.compose_filters([filter1, filter2], mode="or")
filtered_view
<GraphView object, directed, with 83 vertices and 76 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x30c3f6de0, at 0x31518e0f0>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x30c3f6de0, at 0x30c3f6960>, False), at 0x30c3f6de0>
graph_draw(
filtered_view,
vertex_size=12,
vertex_text_color='black',
vertex_text=filtered_view.vp['node_id_decoded'],
)

<VertexPropertyMap object with value type 'vector<double>', for Graph 0x30c3f6de0, at 0x315dbf410>
Analyse the Rhea network#
Now that we’ve shown how to build and filter the Rhea network, what can we actually do with it to start generating interesting insights?
We could start by answering the following basic questions:
Which ChEBI compounds are mostly commonly involved in Rhea reactions?
Which reactions have the largest number of compounds involved?
What are the ‘bottleneck’ reactions? (i.e. betweenness on reactions that share a compound)
Identify the top metabolic ‘hub’ compounds#
filter1 = lambda v: onion.core.graph.vp['layer_decoded'][v] != 'rhea_ec'
filtered_view = onion.searcher.compose_filters(filter_funcs=[filter1], mode="or")
filtered_view
<GraphView object, directed, with 31506 vertices and 83885 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x316165fd0, at 0x30c3f6f60>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x316165fd0, at 0x316166f00>, False), at 0x316165fd0>
onionnet.exporter.export_info(filtered_view, mode='v')
| v_int | layer_hash | node_id_hash | node_id | Equation | ChEBI identifier | chebi_name | EC number | Enzymes | Gene Ontology | ... | ec_level | node_id_decoded | equation_decoded | chebi_identifier_decoded | chebi_name_decoded | ec_number_decoded | gene_ontology_decoded | cross_reference_reactome_decoded | layer_decoded | ec_level_decoded | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4258.0 | 0 | ... | 0 | RHEA:21252 | (S)-2-hydroxyglutarate + A = 2-oxoglutarate + AH2 | CHEBI:16782;CHEBI:13193;CHEBI:16810;CHEBI:17499 | (S)-2-hydroxyglutarate;A;2-oxoglutarate;AH2 | EC:1.1.99.2 | GO:0047545 2-hydroxyglutarate dehydrogenase ac... | nan | rhea_reactionid | nan |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 44340.0 | 1 | ... | 0 | RHEA:21256 | 3-phosphoshikimate + phosphoenolpyruvate = 5-O... | CHEBI:145989;CHEBI:58702;CHEBI:57701;CHEBI:43474 | 3-phosphoshikimate;phosphoenolpyruvate;5-O-(1-... | EC:2.5.1.19 | GO:0003866 3-phosphoshikimate 1-carboxyvinyltr... | nan | rhea_reactionid | nan |
| 2 | 2 | 0 | 2 | 2 | 2 | 2 | 2 | 2 | 3112.0 | 2 | ... | 0 | RHEA:21260 | [thioredoxin]-disulfide + L-methionine + H2O =... | CHEBI:50058;CHEBI:57844;CHEBI:15377;CHEBI:5877... | L-cystine residue;L-methionine;H2O;L-methionin... | EC:1.8.4.14 | GO:0033745 L-methionine-(R)-S-oxide reductase ... | nan | rhea_reactionid | nan |
| 3 | 3 | 0 | 3 | 3 | 3 | 3 | 3 | 3 | 14321.0 | 3 | ... | 0 | RHEA:21264 | glycolate + A = glyoxylate + AH2 | CHEBI:29805;CHEBI:13193;CHEBI:36655;CHEBI:17499 | glycolate;A;glyoxylate;AH2 | EC:1.1.99.14 | GO:0019154 glycolate dehydrogenase activity | nan | rhea_reactionid | nan |
| 4 | 4 | 0 | 4 | 4 | 4 | 4 | 4 | 4 | 0.0 | 4 | ... | 0 | RHEA:21268 | (R)-canadine + 2 NADP(+) = berberine + 2 NADPH... | CHEBI:18146;CHEBI:58349;CHEBI:16118;CHEBI:5778... | (R)-canadine;NADP(+);berberine;NADPH;H(+) | EC:1.5.1.31 | GO:0050623 berberine reductase activity | nan | rhea_reactionid | nan |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 31501 | 31501 | 1 | 31501 | 31501 | 17783 | 17258 | 30642 | 13 | NaN | 6 | ... | 0 | CHEBI:144586 | nan | nan | 4-hydroxy-2-oxobutanal | nan | nan | nan | rhea_chebiid | nan |
| 31502 | 31502 | 1 | 31502 | 31502 | 17783 | 17258 | 30643 | 13 | NaN | 6 | ... | 0 | CHEBI:57639 | nan | nan | 4-(L-alanin-3-yl)-2-hydroxy-cis,cis-muconate 6... | nan | nan | nan | rhea_chebiid | nan |
| 31503 | 31503 | 1 | 31503 | 31503 | 17783 | 17258 | 30644 | 13 | NaN | 6 | ... | 0 | CHEBI:18167 | nan | nan | alpha-maltose | nan | nan | nan | rhea_chebiid | nan |
| 31504 | 31504 | 1 | 31504 | 31504 | 17783 | 17258 | 30645 | 13 | NaN | 6 | ... | 0 | CHEBI:52025 | nan | nan | an 8-hydroxyfurocoumarin | nan | nan | nan | rhea_chebiid | nan |
| 31505 | 31505 | 1 | 31505 | 31505 | 17783 | 17258 | 30646 | 13 | NaN | 6 | ... | 0 | CHEBI:52028 | nan | nan | an 8-methoxyfurocoumarin | nan | nan | nan | rhea_chebiid | nan |
31506 rows × 22 columns
onionnet.exporter.export_info(filtered_view, mode='v')['layer_decoded'].value_counts()
layer_decoded
rhea_reactionid 17783
rhea_chebiid 13723
Name: count, dtype: int64
filtered_view
<GraphView object, directed, with 31506 vertices and 83885 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x316165fd0, at 0x30c3f6f60>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x316165fd0, at 0x316166f00>, False), at 0x316165fd0>
topx_num = 20
gview = filtered_view
# 1. compute degrees in the filtered view
deg_map = gview.degree_property_map("total")
# 2. collect only those vertices that are still in view AND are compounds
compound_vs = [v for v in gview.vertices() if gview.vp['layer_decoded'][v] == 'rhea_chebiid']
# 3. sort by degree, descending, take top x
topx = sorted(compound_vs, key=lambda v: deg_map[v], reverse=True)[:topx_num]
# 4. print or return
print(f"Top {topx_num} hub compounds in filtered Rhea graph:")
for v in topx:
name = gview.vp['chebi_name_decoded'][v] # or however you store the compound label
print(f" {name:12s} — {int(deg_map[v])} reactions")
Top 20 hub compounds in filtered Rhea graph:
H(+) — 9932 reactions
H2O — 6485 reactions
O2 — 2851 reactions
CoA — 1567 reactions
NADP(+) — 1335 reactions
NADPH — 1329 reactions
ATP — 1328 reactions
NAD(+) — 1207 reactions
diphosphate — 1188 reactions
NADH — 1136 reactions
CO2 — 1058 reactions
phosphate — 1029 reactions
S-adenosyl-L-methionine — 935 reactions
ADP — 865 reactions
FMN — 861 reactions
S-adenosyl-L-homocysteine — 854 reactions
FMNH2 — 852 reactions
UDP — 637 reactions
NH4(+) — 543 reactions
AMP — 529 reactions
Identify which reactions involve the largest number of compounds#
# 1. compute degrees in the filtered view
deg_map = gview.degree_property_map("total")
# 2. collect only those vertices that are still in view AND are reactions
reaction_vs = [v for v in gview.vertices() if gview.vp['layer_decoded'][v] == 'rhea_reactionid']
# 3. sort by degree, descending, take top x
topx = sorted(reaction_vs, key=lambda v: deg_map[v], reverse=True)[:topx_num]
# 4. print or return
print(f"Top {topx_num} reactions in filtered Rhea graph by number of compounds involved:")
for v in topx:
name = gview.vp['equation_decoded'][v] # or however you store the compound label
print(f" {gview.vp['node_id_decoded'][v]}\t{int(deg_map[v])} compounds involved:\t{name:12s}")
Top 20 reactions in filtered Rhea graph by number of compounds involved:
RHEA:64544 16 compounds involved: L-tyrosine + holo-[ACP] + 7 malonyl-CoA + acetyl-CoA + 8 AH2 + 2 S-adenosyl-L-methionine + ATP + 4 H(+) = N-[(4E,6E,10S,12Z,14E)-6,10-dimethyl-3-oxohexadeca-4,6,12,14-tetraenoyl]-L-tyrosyl-[ACP] + 8 A + AMP + 2 S-adenosyl-L-homocysteine + 7 CO2 + diphosphate + 8 CoA + 6 H2O
RHEA:69564 16 compounds involved: 3 L-isoleucine + L-asparagine + L-histidine + L-leucine + L-ornithine + L-lysine + L-cysteine + L-aspartate + L-phenylalanine + L-glutamate + 12 ATP = bacitracin A + 12 AMP + 12 diphosphate + H2O + 12 H(+)
RHEA:67324 15 compounds involved: L-serine + 7 malonyl-CoA + acetyl-CoA + 2 S-adenosyl-L-methionine + ATP + 8 NADPH + 11 H(+) = (5S)-3-[(2E,6R,8E,10E,12E)-2,6-dimethyltetradeca-2,8,10,12-tetraenoyl]-5-(hydroxymethyl)pyrrolidine-2,4-dione + AMP + 2 S-adenosyl-L-homocysteine + 7 CO2 + diphosphate + 8 NADP(+) + 8 CoA + 6 H2O
RHEA:67264 14 compounds involved: (2S,4S)-4-hydroxy-4-methylglutamate + 8 malonyl-CoA + 3 S-adenosyl-L-methionine + ATP + 8 NADPH + 11 H(+) = (2S)-3-[(2S)-3,5-dioxo-4-[(2E,4R,6R,8E,10E,12E)-4,6,12-trimethyltetradeca-2,8,10,12-tetraenoyl]pyrrolidin-2-yl]-2-hydroxy-2-methylpropanoate + AMP + 3 S-adenosyl-L-homocysteine + 8 CO2 + diphosphate + 8 NADP(+) + 8 CoA + 6 H2O
RHEA:67288 14 compounds involved: L-leucine + 8 malonyl-CoA + 4 S-adenosyl-L-methionine + ATP + 9 NADPH + 12 H(+) = (5S)-5-(2-methylpropyl)-3-[(2E,6R,8E,10E,12E)-6,8,10,12-tetramethyltetradeca-2,8,10,12-tetraenoyl]-2,5-dihydro-1H-pyrrol-2-one + AMP + 4 S-adenosyl-L-homocysteine + 8 CO2 + diphosphate + 9 NADP(+) + 8 CoA + 7 H2O
RHEA:67316 14 compounds involved: (2S,4R)-4-hydroxy-4-methylglutamate + 8 malonyl-CoA + 3 S-adenosyl-L-methionine + ATP + 8 NADPH + 11 H(+) = (2R)-3-[(2S)-3,5-dioxo-4-[(2E,4R,6R,8E,10E,12E)-4,6,12-trimethyltetradeca-2,8,10,12-tetraenoyl]pyrrolidin-2-yl]-2-hydroxy-2-methylpropanoate + AMP + 3 S-adenosyl-L-homocysteine + 8 CO2 + diphosphate + 8 NADP(+) + 8 CoA + 6 H2O
RHEA:72015 14 compounds involved: malate + 6 malonyl-CoA + acetyl-CoA + 2 AH2 + 2 S-adenosyl-L-methionine + 5 NADPH + 9 H(+) = trihazone A + 2 A + 2 S-adenosyl-L-homocysteine + 6 CO2 + 5 NADP(+) + 7 CoA + 6 H2O
RHEA:64512 12 compounds involved: (3E,5E,7S)-5,7-dimethyl-2-oxonona-3,5-dienyl-[ACP] + 4 malonyl-CoA + AH2 + S-adenosyl-L-methionine + 3 H(+) = 6-[(3E,5E,7S)-5,7-dimethyl-2-oxonona-3,5-dienyl]-2,4-dihydroxy-3-methylbenzaldehyde + holo-[ACP] + A + S-adenosyl-L-homocysteine + 4 CO2 + 4 CoA + H2O
RHEA:64528 12 compounds involved: decanoyl-[ACP] + 4 malonyl-CoA + AH2 + S-adenosyl-L-methionine + 3 H(+) = 2,4-dihydroxy-3-methyl-6-(2-oxoundecyl)benzaldehyde + holo-[ACP] + A + S-adenosyl-L-homocysteine + 4 CO2 + 4 CoA + H2O
RHEA:81147 12 compounds involved: holo-[ACP] + 8 malonyl-CoA + acetyl-CoA + 5 AH2 + 8 NADPH + 16 H(+) = (3R)-hydroxyoctadeca-4,10-dienoyl-[ACP] + 5 A + 8 CO2 + 8 NADP(+) + 9 CoA + 7 H2O
RHEA:83279 12 compounds involved: 5,10-methylenetetrahydrofolate + uridine(34) in tRNA + taurine + GTP + A + H2O = 5-taurinomethyluridine(34) in tRNA + 7,8-dihydrofolate + GDP + AH2 + phosphate + H(+)
RHEA:37067 11 compounds involved: N(6)-dimethylallyladenosine(37) in tRNA + (sulfur carrier)-SH + AH2 + 2 S-adenosyl-L-methionine = 2-methylsulfanyl-N(6)-dimethylallyladenosine(37) in tRNA + (sulfur carrier)-H + 5'-deoxyadenosine + L-methionine + A + S-adenosyl-L-homocysteine + 2 H(+)
RHEA:37075 11 compounds involved: N(6)-L-threonylcarbamoyladenosine(37) in tRNA + (sulfur carrier)-SH + AH2 + 2 S-adenosyl-L-methionine = 2-methylsulfanyl-N(6)-L-threonylcarbamoyladenosine(37) in tRNA + (sulfur carrier)-H + 5'-deoxyadenosine + L-methionine + A + S-adenosyl-L-homocysteine + 2 H(+)
RHEA:37087 11 compounds involved: L-aspartate(89)-[ribosomal protein uS12]-hydrogen + (sulfur carrier)-SH + AH2 + 2 S-adenosyl-L-methionine = 3-methylsulfanyl-L-aspartate(89)-[ribosomal protein uS12]-hydrogen + (sulfur carrier)-H + 5'-deoxyadenosine + L-methionine + A + S-adenosyl-L-homocysteine + 2 H(+)
RHEA:42852 11 compounds involved: holo-[2-methylbutanoate polyketide synthase] + 2 malonyl-CoA + S-adenosyl-L-methionine + 2 NADPH + 3 H(+) = (S)-2-methylbutanoyl-[2-methylbutanoate polyketide synthase] + S-adenosyl-L-homocysteine + 2 CO2 + 2 NADP(+) + 2 CoA + H2O
RHEA:51348 11 compounds involved: 7 malonyl-CoA + acetyl-CoA + 10 AH2 + 5 S-adenosyl-L-methionine + 2 H(+) = dehydroprobetaenone I + 10 A + 5 S-adenosyl-L-homocysteine + 7 CO2 + 8 CoA + 6 H2O
RHEA:53504 11 compounds involved: 5-amino-1-(5-phospho-beta-D-ribosyl)imidazole + AH2 + S-adenosyl-L-methionine = 5-hydroxybenzimidazole + 5'-deoxyadenosine + formate + L-methionine + A + NH4(+) + phosphate + 2 H(+)
RHEA:63824 11 compounds involved: 2 3-(4-hydroxyphenyl)pyruvate + AH2 + 2 ATP + O2 = aspulvinone E + A + 2 AMP + CO2 + 2 diphosphate + H2O + H(+)
RHEA:64504 11 compounds involved: propanoyl-CoA + 3 malonyl-CoA + AH2 + 2 S-adenosyl-L-methionine + H(+) = 2-ethyl-4,6-dihydroxy-3,5-dimethylbenzaldehyde + A + 2 S-adenosyl-L-homocysteine + 3 CO2 + 4 CoA + H2O
RHEA:64508 11 compounds involved: 4 malonyl-CoA + acetyl-CoA + AH2 + S-adenosyl-L-methionine + 3 H(+) = 2,4-dihydroxy-3-methyl-6-(2-oxopropyl)benzaldehyde + A + S-adenosyl-L-homocysteine + 4 CO2 + 5 CoA + H2O
Finding bottleneck reactions via betweenness centrality#
from graph_tool.topology import label_largest_component
from graph_tool.centrality import betweenness
# — assume you already have —
# gview: GraphView of your full Rhea graph
# vtype = gview.vp['type'] # “compound” or “reaction”
# name = gview.vp['name'] # human-readable label
# (and you’ve built compound_vs similarly)
# 1. Extract reaction vertices from your view
reaction_vs = [v for v in gview.vertices() if gview.vp['layer_decoded'][v] == 'rhea_reactionid']
# 2. Build a new undirected graph h of only those reactions
h = Graph(directed=False)
h.vp['orig_id'] = h.new_vertex_property('int') # to map back to gview
orig2new = {}
for orig in reaction_vs:
nv = h.add_vertex()
orig2new[orig] = nv
h.vp['orig_id'][nv] = int(orig)
# 3. For each compound in the view, fully connect its incident reactions
compound_vs = [v for v in gview.vertices() if gview.vp['layer_decoded'][v] == 'rhea_chebiid']
for comp in compound_vs:
# gather reactions incident to this compound (in the view)
inc_reactions = []
for e in comp.all_edges():
# e.source() or e.target() may be the compound; pick the other end
other = e.target() if e.source() == comp else e.source()
if gview.vp['layer_decoded'][other] == 'reaction':
inc_reactions.append(other)
# fully connect each pair of those reactions in h
for i in range(len(inc_reactions)):
for j in range(i+1, len(inc_reactions)):
h.add_edge(orig2new[inc_reactions[i]],
orig2new[inc_reactions[j]])
# 4. Compute betweenness centrality on the reaction–reaction graph
vertex_btw, _ = betweenness(h)
# 5. Report the top 5 bottleneck reactions
btw_list = sorted(h.vertices(),
key=lambda v: vertex_btw[v],
reverse=True)[:5]
print("Top 5 bottleneck reactions in your filtered graph:")
for v in btw_list:
orig = h.vp['orig_id'][v]
label = gview.vp['node_id_decoded'][gview.vertex(orig)]
print(f" {label:<20s} — betweenness = {vertex_btw[v]:.20f} \t {gview.vp['equation_decoded'][v]}")
Top 5 bottleneck reactions in your filtered graph:
RHEA:21252 — betweenness = 0.00000000000000000000 (S)-2-hydroxyglutarate + A = 2-oxoglutarate + AH2
RHEA:21256 — betweenness = 0.00000000000000000000 3-phosphoshikimate + phosphoenolpyruvate = 5-O-(1-carboxyvinyl)-3-phosphoshikimate + phosphate
RHEA:21260 — betweenness = 0.00000000000000000000 [thioredoxin]-disulfide + L-methionine + H2O = L-methionine (R)-S-oxide + [thioredoxin]-dithiol
RHEA:21264 — betweenness = 0.00000000000000000000 glycolate + A = glyoxylate + AH2
RHEA:21268 — betweenness = 0.00000000000000000000 (R)-canadine + 2 NADP(+) = berberine + 2 NADPH + H(+)
See that none of the top 5 reactions actually have a betweenness score above 0… this is likely because all reactions have one of the top most popular metabolite compounds involved (e.g. H20, H, ATP, etc.). So these super-connectors means there are no single reactions that form bottelnecks (at least if we consider these superconnectors).
Let’s try removing those that have extremely high connectivity to see if that influences it
# assume gview is your filtered GraphView of the full KG
vtype = gview.vp['layer_decoded'] #gview.vp['type']
deg = gview.degree_property_map('total')
# create a vertex filter that excludes hub compounds
vfilt = gview.new_vertex_property('bool')
for v in gview.vertices():
if vtype[v]=='rhea_chebiid' and deg[v] > 50:
vfilt[v] = False
else:
vfilt[v] = True
# build a new view without hubs
g_nohubs = GraphView(gview, vfilt=vfilt)
g_nohubs
<GraphView object, directed, with 31396 vertices and 35456 edges, 21 internal vertex properties, 13 internal edge properties, edges filtered by (<EdgePropertyMap object with value type 'bool', for Graph 0x31518d370, at 0x306f19700>, False), vertices filtered by (<VertexPropertyMap object with value type 'bool', for Graph 0x31518d370, at 0x31518f3e0>, False), at 0x31518d370>
# 1. Extract reaction vertices from your view
reaction_vs = [v for v in g_nohubs.vertices() if g_nohubs.vp['layer_decoded'][v] == 'rhea_reactionid']
# 2. Build a new undirected graph h of only those reactions
h = Graph(directed=False)
h.vp['orig_id'] = h.new_vertex_property('int') # to map back to gview / g_nohubs
orig2new = {}
for orig in reaction_vs:
nv = h.add_vertex()
orig2new[orig] = nv
h.vp['orig_id'][nv] = int(orig)
# 3. For each compound in the view, fully connect its incident reactions
compound_vs = [v for v in g_nohubs.vertices() if g_nohubs.vp['layer_decoded'][v] == 'rhea_chebiid']
for comp in compound_vs:
# gather reactions incident to this compound (in the view)
inc_reactions = []
for e in comp.all_edges():
# e.source() or e.target() may be the compound; pick the other end
other = e.target() if e.source() == comp else e.source()
if g_nohubs.vp['layer_decoded'][other] == 'reaction':
inc_reactions.append(other)
# fully connect each pair of those reactions in h
for i in range(len(inc_reactions)):
for j in range(i+1, len(inc_reactions)):
h.add_edge(orig2new[inc_reactions[i]],
orig2new[inc_reactions[j]])
# 4. Compute betweenness centrality on the reaction–reaction graph
vertex_btw, _ = betweenness(h)
# 5. Report the top 5 bottleneck reactions
btw_list = sorted(h.vertices(),
key=lambda v: vertex_btw[v],
reverse=True)[:5]
print("Top 5 bottleneck reactions in your filtered graph:")
for v in btw_list:
orig = h.vp['orig_id'][v]
label = g_nohubs.vp['node_id_decoded'][g_nohubs.vertex(orig)]
print(f" {label:<20s} — betweenness = {vertex_btw[v]:.20f} \t {g_nohubs.vp['equation_decoded'][v]}")
Top 5 bottleneck reactions in your filtered graph:
RHEA:21252 — betweenness = 0.00000000000000000000 (S)-2-hydroxyglutarate + A = 2-oxoglutarate + AH2
RHEA:21256 — betweenness = 0.00000000000000000000 3-phosphoshikimate + phosphoenolpyruvate = 5-O-(1-carboxyvinyl)-3-phosphoshikimate + phosphate
RHEA:21260 — betweenness = 0.00000000000000000000 [thioredoxin]-disulfide + L-methionine + H2O = L-methionine (R)-S-oxide + [thioredoxin]-dithiol
RHEA:21264 — betweenness = 0.00000000000000000000 glycolate + A = glyoxylate + AH2
RHEA:21268 — betweenness = 0.00000000000000000000 (R)-canadine + 2 NADP(+) = berberine + 2 NADPH + H(+)
# 1. isolate the largest component of h
comp = label_largest_component(h)
h_largest = GraphView(h, vfilt=comp)
# 2. compute betweenness on that view
vertex_btw, _ = betweenness(h_largest)
# 3. pick the top 5 within h_largest
btw_list = sorted(h_largest.vertices(),
key=lambda v: vertex_btw[v],
reverse=True)[:5]
print("Top 5 bottleneck reactions in your filtered graph:")
for v in btw_list:
# recover the original reaction index
orig_idx = h_largest.vp['orig_id'][v]
# get back the vertex in your filtered Rhea graph (without hubs)
rv = g_nohubs.vertex(orig_idx)
# look up human‐readable fields
label = g_nohubs.vp['node_id_decoded'][rv]
equation = g_nohubs.vp['equation_decoded'][rv]
print(f" {label:<20s} — betweenness = {vertex_btw[v]:.30f} \t {equation}")
Top 5 bottleneck reactions in your filtered graph:
RHEA:21252 — betweenness = 0.000000000000000000000000000000 (S)-2-hydroxyglutarate + A = 2-oxoglutarate + AH2
It seems that it still isn’t possible to find bottleneck reactions per se, probably because of the high level of shared betweenness for all of the reactions and their shared metabolites involved in each reaction (even after removal of top culprits and reduction to the largest connected component).